Dnes 19.9. jsem dostal mail od paní koordinátorky z VŠE, která mi přeposlala dopis s nabídkou ke studiu v Austrálii. Přihlášku jsem poslal expresně dne 7.9.2012.
Nabídka ke studiu obsahuje nějaké kecy o tom, že mě přijali, ale je potřeba dále odeslat nějaké věci ke vyřízení vízy. Email z Austrálie tedy obsahuje jedno PDF o tom, co udělat dál. Druhé PDF je o tom, že mi uznali předměty, které jsem si navolil. A třetí PDF obsahuje formuláře, které se musí vyplnit, ručně podepsat a poslat zpět spolu s prachy. Mělo by to stačit jen emailem, tak uvidíme.
středa 19. září 2012
sobota 15. září 2012
Haskell - 3. kapitola
Vzory (patterns)
- můžeme definovat pro každý parametr jiné tělo fce
- lucky :: (Integral a) => a -> String
- lucky 7 = "LUCKY NUMBER SEVEN!"
- lucky x = "Sorry, you're out of luck, pal!"
Pro číslo 7 a pro ostatní čísla jsou definovány různá těla fce.
Poznámka: tady jsem si všiml zajímavosti. První řádek specifikuje typ fce (viz předchozí kapitola). Když ho dáme pryč, typ fce bude: lucky :: (Eq a, Num a) => a -> [Char]. Nejspíš je to způsobený odvozováním typu. Když nechám jen poslední řádek s podmínkou pro x obecně, typ fce bude: lucky :: t -> [Char].
Příklad: fce pro výpočet faktoriálu pomocí vzorů (řešení str.36 dole)? A pak zkuste vypočítat faktoriál pro 100 000 a koukejte se na Matrix.
Sčítání 2 vektorů
- addVectors :: (Num a) => (a, a) -> (a, a) -> (a, a)
- addVectors (x1, y1) (x2, y2) = (x1 + x2, y1 + y2)
Vlastní implementace fce head
- head' :: [a] -> a
- head' [] = error "Can't call head on an empty list, dummy!"
- head' (x:_) = x
(x:_) - x zde reprezentuje první prvek z listu a _ jsou zbývající prvky - díky znaku : je zajištěno, že to musí být list. ( a ) jsou potřeba, pokud parsujeme více prvků najednou (zde parsujeme první prvek a zbytek listu)
As patterns
Někdy je potřeba získat celý výraz a i výraz rozdělený podle patternu.- ghci> capital "Dracula"
- "The first letter of Dracula is D"
Fce capital vrátí větu, která obsahuje původní výraz i první písmeno z původního výrazu. Lze to udělat takto:
- capital :: String -> String
- capital "" = "Empty string, whoops!"
- capital (x:xs) = "The first letter of " ++ x:xs ++ " is " ++ [x]
ale i hezčím způsobem:
- capital :: String -> String
- capital "" = "Empty string, whoops!"
- capital all@(x:xs) = "The first letter of " ++ all ++ " is " ++ [x]
Guards
- jedna z možností větvení- bmiTell :: (RealFloat a) => a -> a -> String
- bmiTell weight height
- | weight / height ^ 2 <= 18.5 = "You're underweight, you emo, you!"
- | weight / height ^ 2 <= 25.0 = "You're supposedly normal. Pffft, I bet you're ugly!"
- | weight / height ^ 2 <= 30.0 = "You're fat! Lose some weight, fatty!"
- | otherwise = "You're a whale, congratulations!"
Where
Předchozí příklad není moc DRY. To lze spravit pomocí konstrukce where:- bmiTell :: (RealFloat a) => a -> a -> String
- bmiTell weight height
- | bmi <= skinny = "You're underweight, you emo, you!"
- | bmi <= normal = "You're supposedly normal. Pffft, I bet you're ugly!"
- | bmi <= fat = "You're fat! Lose some weight, fatty!"
- | otherwise = "You're a whale, congratulations!"
- where bmi = weight / height ^ 2
- skinny = 18.5
- normal = 25.0
- fat = 30.0
definujeme jednu vnitřní funkci a tři konstanty na konci vnější funkce. Scope těchto vnitřních fcí a konstant je pro celou vnější fci. Pozor na odsazení jejich odsazení, musejí být stejně odsazené.
Lze použít i pattern matching:
- initials :: String -> String -> String
- initials firstname lastname = [f] ++ ". " ++ [l] ++ "."
- where (f:_) = firstname
- (l:_) = lastname
where funkce mohou být i složitější:
- calcBmis :: (RealFloat a) => [(a, a)] -> [a]
- calcBmis xs = [bmi w h | (w, h) <- xs]
- where bmi weight height = weight / height ^ 2
Zde definujeme vnější funkci calcBmis, kterou používá ve svém těle vnitřní funkci bmi. Vnitřní fce bmi není dostupná zvenku, ale jen uvnitř calcBmis.
Let
- cylinder :: (RealFloat a) => a -> a -> a
- cylinder r h =
- let sideArea = 2 * pi * r * h
- topArea = pi * r ^2
- in sideArea + 2 * topArea
let na rozdíl od where prvně přiřazuje a až pak provádí funkci v bloku in. Rozdíl je též ve scope definovaných funkcí. Let není vidět mezi guardy jako u where. let je také výraz:
- ghci> 4 * (let a = 9 in a + 1) + 2
- 42
Přepis funkce calcBmis do podoby s let:
- calcBmis :: (RealFloat a) => [(a, a)] -> [a]
- calcBmis xs = [bmi | (w, h) <- xs, let bmi = w / h ^ 2]
Rozdíl ve scope, když v ghci napíšeme let s konstrukcí in či bez ní:
- ghci> let zoot x y z = x * y + z
- ghci> zoot 3 9 2
- 29
- ghci> let boot x y z = x * y + z in boot 3 4 2
- 14
- ghci> boot
- <interactive>:1:0: Not in scope: `boot'
Case
- describeList :: [a] -> String
- describeList xs = "The list is " ++ case xs of [] -> "empty."
- [x] -> "a singleton list."
- xs -> "a longer list."
Klasika, lze tu použít i pattern matching.
středa 12. září 2012
B-strom
Dnes mě zaujal algoritmus o B-stromu, tak o tom zkusím stručně napsat, abych do budoucna na to nezapomněl. Veškeré poznatky a obrázky jsou z kurzu Algorithms, Part I z webu Coursera.org


- strom může obsahovat uzel s jedním klíčem (binární strom) nebo s dvěma klíči a třemi větvemi, kde:
- musíme zajistit, aby strom byl pořád pefektně vyvážený - strom musí růst směrem z kořene nahoru. Existuje několik situací:
Přidání prvku (klíč-hodnota) tam, kde uzel obsahuje jen 1 klíč - přidáme do toho samého uzlu a nový klíč umístíme buď nalevo (pro klíče menší) nebo napravo (pro klíče větší) od klíče, který tam už bylo.

Přidání prvku tam, kde uzel obsahuje 2 klíče - přidáme klíč do příslušného uzlu jak v předchozím příkladě. Jenže pak vznikne uzel s třemi klíči a 4 větvemi a to by nešlo. Tento uzel se třemi klíči rozdělíme do třech uzlů - prostřední prvek posuneme nahoru a do spodních dvou rozdělíme po dvou 4 větve.

Přidání prvku tam, kde uzel a jeho rodič obsahuje 2 klíče - viz předchozí příklad. Ten se opakuje do té doby, než se vše dostane až do kořene. Kořen se 3 prvky rozdělíme tak, že prostřední posuneme o úroveň nahoru, a tak fakticky vznikne nový kořen a strom vzroste o 1 úroveň.



Binární strom
Binární strom je graf, kdy má každý uzel (kromě listů) 2 větve s potomky. Uzel je tvořen klíčem a hodnotou (key-value), kdy klíče lze mezi sebou porovnávat.Binární vyhledávací strom
uzel (předchůdce) má 2 větve - levá větev obsahuje jen potomky s menším klíčem a pravá větev jen potomky s větší klíčem.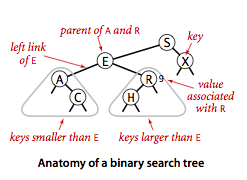
2-3 vyhledávací strom
- tento strom je perfektně vyvážený = všechny cesty z kořene (root) stromu k listům jsou stejně dlouhé
- strom může obsahovat uzel s jedním klíčem (binární strom) nebo s dvěma klíči a třemi větvemi, kde:
- levá větev obsahuje potomky s menším klíčem
- prostřední větev obsahuje klíče větší než první klíč a menší než druhý klíč z předchůdce
- třetí větev obsahuje potomky s větším klíčem
- musíme zajistit, aby strom byl pořád pefektně vyvážený - strom musí růst směrem z kořene nahoru. Existuje několik situací:
Přidání prvku (klíč-hodnota) tam, kde uzel obsahuje jen 1 klíč - přidáme do toho samého uzlu a nový klíč umístíme buď nalevo (pro klíče menší) nebo napravo (pro klíče větší) od klíče, který tam už bylo.
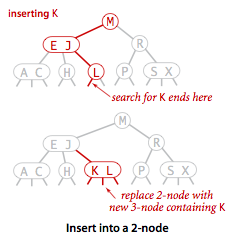
- chci přidat K - vyhledám místo, kam ho přidám - do uzlu obsahující L
- přidám ho nalevo od L, protože K je menší než L
Přidání prvku tam, kde uzel obsahuje 2 klíče - přidáme klíč do příslušného uzlu jak v předchozím příkladě. Jenže pak vznikne uzel s třemi klíči a 4 větvemi a to by nešlo. Tento uzel se třemi klíči rozdělíme do třech uzlů - prostřední prvek posuneme nahoru a do spodních dvou rozdělíme po dvou 4 větve.
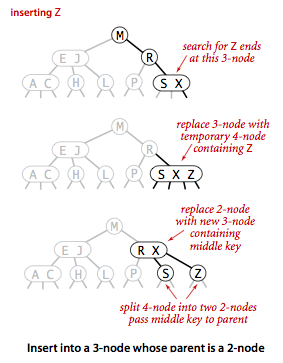
- chci přidat prvek s klíčem Z - přidám ho do uzlu, který obsahuje klíče S a X
- vznikl uzel se 3 klíči S, X a Z a 4 větvemi - a to by nešlo
- rozdělíme tento uzel do 3 uzlů - prostřední klíč posuneme o úroveň výš a zbývající 2 klíče se stanou následnými uzly nalevo (menší klíč) a napravo (větší klíč) od prostředního klíče
{kind=link}
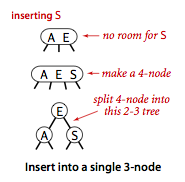
Přidání prvku tam, kde uzel a jeho rodič obsahuje 2 klíče - viz předchozí příklad. Ten se opakuje do té doby, než se vše dostane až do kořene. Kořen se 3 prvky rozdělíme tak, že prostřední posuneme o úroveň nahoru, a tak fakticky vznikne nový kořen a strom vzroste o 1 úroveň.
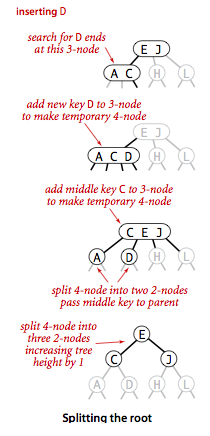
- chci přidat D - přidám do uzlu obsahující A a C
- mám uzel s klíči A, C a D a 4 větve - jedna pro prvky menší než A, druhá pro prvky mezi A a C, třetí mezi C a D a čtvrtá větší než D -> to by ale nešlo
- proto rozdělíme tento uzel na 3 různé uzly - prostřední uzel obsahující klíč C posunu o úroveň nahoru, uzly s klíči A a D budou jeho levými (A) a pravými potomky
- pokračuji, dokud je strom správně vyvážený a uzly obsahující max. 2 klíče
- pokud dojdu až na kořen, tak se strom zvýší o jednu úroveň
B-strom
- důvod: zrychlení vyhledávání dat
- zobecnění 2-3 stromu - uzly mohou mít mnoho klíčů
- listy obsahují skutečné klíče, rodiče obsahují kopie těchto klíčů a vytváří tak odkaz na listy
Vyhledávání klíče E - B-strom o velikosti uzlu max. 6 klíčů

- kořen obsahuje kopie klíčů * a K. E je větší než * a menší než K - půjdeme do uzlu potomka, který začíná znakem * (tzn. obsahuje klíče, které jsou větší nebo rovna znaku *). Znak * je úplně nejmenším znakem, proto je to hned první větev.
- druhý uzel také obsahuje kopie klíčů * D H, protože to není list. E je větší než D a menší než H - půjdeme do druhé větve.
- následující uzel už je listem, proto zde najdeme již klíč E
Vkládání nového klíče

- chci vložit klíč A - vyhledám příslušný list a vložím
- v tomto případě je list plný - rozdělí se na dva stejně velké listy * A B a C E F - do rodičovského uzlu jde kopie prvního klíče z druhého listu - v tomto případě je to prvek C
- rodičovský uzel (zároveň kořen) je taky plný - taky se rozdělí na dva stejně veliké uzly * C H a K Q U. Kopie prvního klíče z prvního a druhého listu vytvoří nový kořen.
Složitost
Binární strom - v průměru má bin. strom složitost 1.39 lg N (logaritmus o základu 2). Logaritmus dvou má proto, že počet uzlů o úroveň níž se zvětšuje vždy o mocniny dvou (1 - 2 - 4 - 8 atd.), 1.39 je asi nějaká konstanta udávající nejpravděpodobnější podoba stromu.
Binární strom může mít složitost až N, když jsou prvky, které jdou do stromu, již předem seřazené.
2-3 strom - díky vyváženosti má složitost v nejhorším případě lg N (když obsahují všechny uzly jen 2 klíče), v nejlepším log3N (když obsahují všechny uzly 3 klíče).
B-strom - záleží na počtu klíčů v uzlu. Pokud má uzel M klíčů, tak složitost je mezi logM-1N (logMN nejde, protože se uzel rozpadne na 2 stejně velké uzly) a logM/2N (to je případ hned po rozpadu na 2 velké části - což je nejhorší případ).
B-strom - záleží na počtu klíčů v uzlu. Pokud má uzel M klíčů, tak složitost je mezi logM-1N (logMN nejde, protože se uzel rozpadne na 2 stejně velké uzly) a logM/2N (to je případ hned po rozpadu na 2 velké části - což je nejhorší případ).
Přihlásit se k odběru:
Komentáře (Atom)